


When scaling event-driven architectures to hundreds of transactions per second, teams often focus on the obvious suspects: database connection pools, instance sizes, and read replicas. But there's a hidden bottleneck that can bring your entire system to its knees and it has nothing to do with your database's capacity.
It's about how long your AWS Lambda functions take to process events.
Let me walk you through a performance problem that emerges at scale and why the solution is counterintuitive.
Terminology
Before we dive in, let's clarify the terms used throughout this post:
| Term | Definition |
|---|---|
| Event | CONTRACT#123What Kafka sends (300 events/second) |
| Record | Individual item within an event that needs to be written to the database |
| Batch | What Lambda receives from Kafka (multiple events) |
The Architecture
Consider a typical event-driven pipeline:
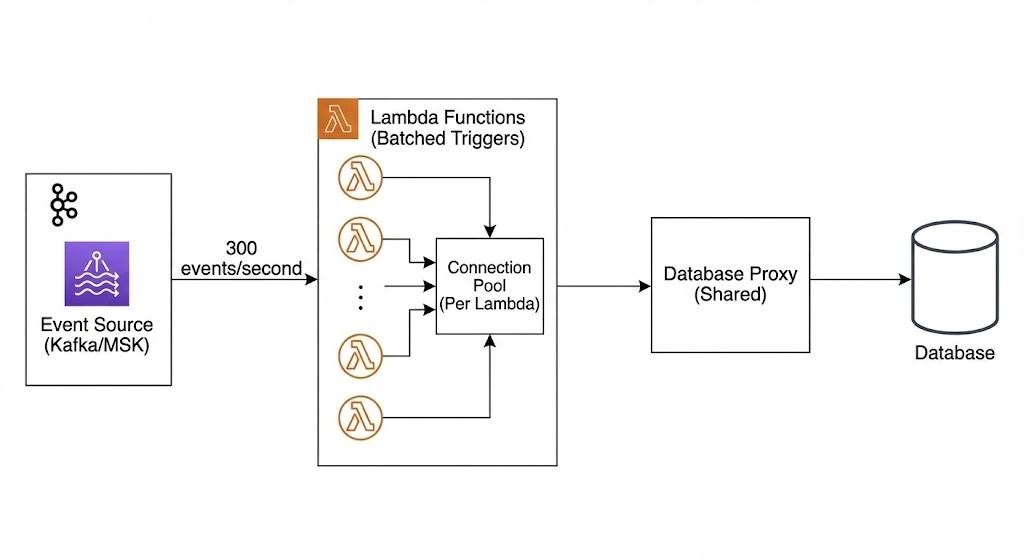
High-throughput event processing architecture: Kafka/MSK streams 300 events per second into batched AWS Lambda functions. Each Lambda uses its own connection pool, connects through a shared database proxy, and writes to a centralized database while managing connections efficiently at scale.
Each Lambda invocation:
- Receives a batch of events from Kafka (say, 300 events)
- Each event contains records to be written to the database
- Processes each record (writes to multiple database tables)
- Uses a connection pool (say, 10 connections)
- Connects through AWS RDS Proxy to the actual database
Sounds reasonable. Let's see where it breaks.
The Cascade Effect
Here's what happens at 300 events per second:
Each record needs to be written to multiple related database tables. A single record might touch 30-40 tables — think of a complex business entity with all its relationships, metadata, and audit trails.
For each record, the Lambda opens a transaction, writes to all these tables sequentially, and commits. Even with fast queries (10-15ms each), the total transaction takes much longer than you'd expect:
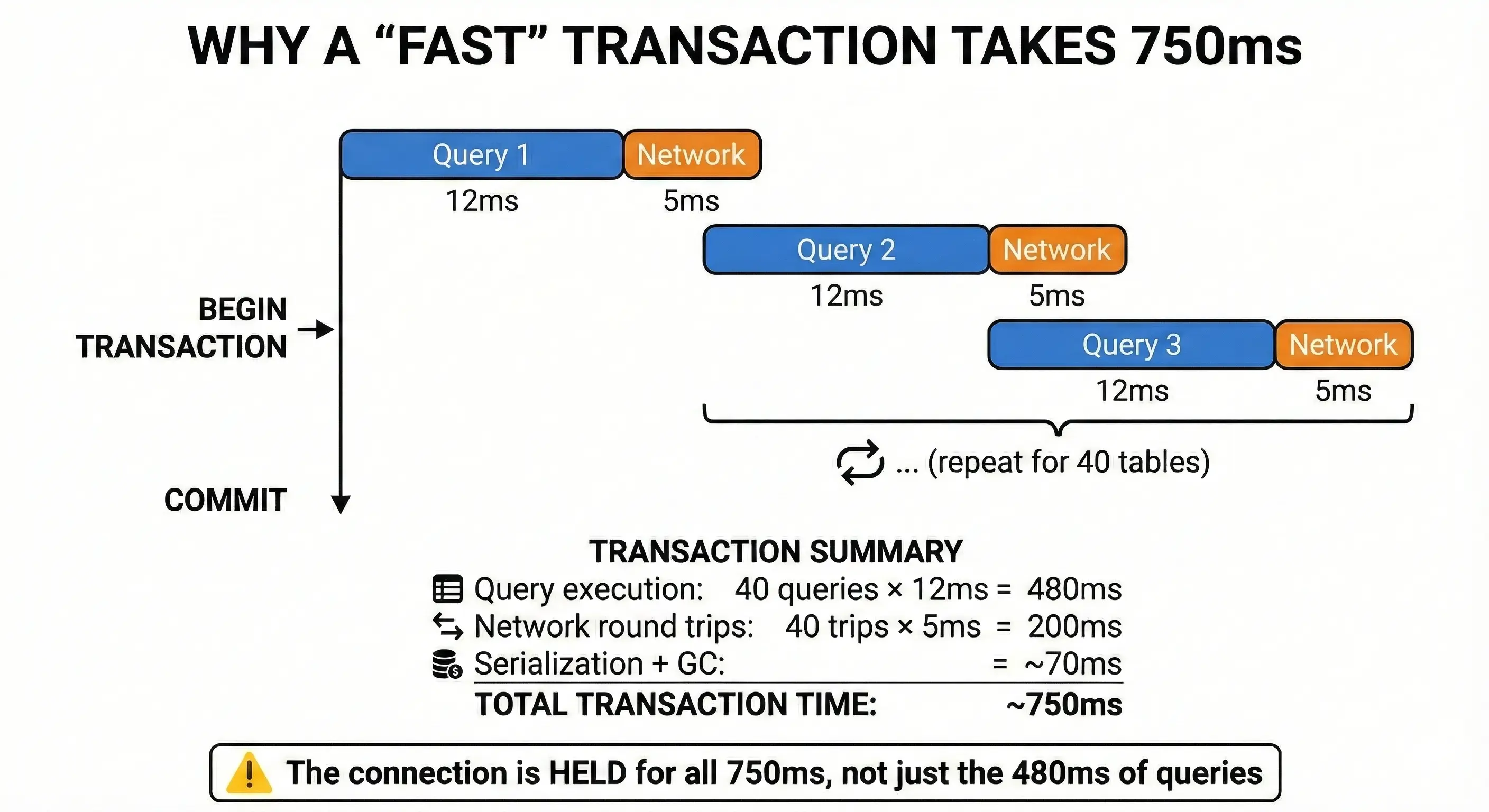
Connection isn’t just about query speed: 12 ms queries plus 5 ms of network overhead, repeated across 40 tables, add up to a 750 ms transaction where the database connection is held the whole time.
This is transaction hold time, the total duration a connection is locked, including all the gaps between queries. It's the silent killer of high-throughput systems.
The Lambda Duration Problem
Now let's calculate how long a Lambda invocation takes:
Since we configured the batch size to 300 and Pool size of 10. We need 300 / 10 = 30 Batches which will be executed sequentially. With an average transaction time of 750 ms it will take :30 Batches * 750 ms = 22,500 ms.
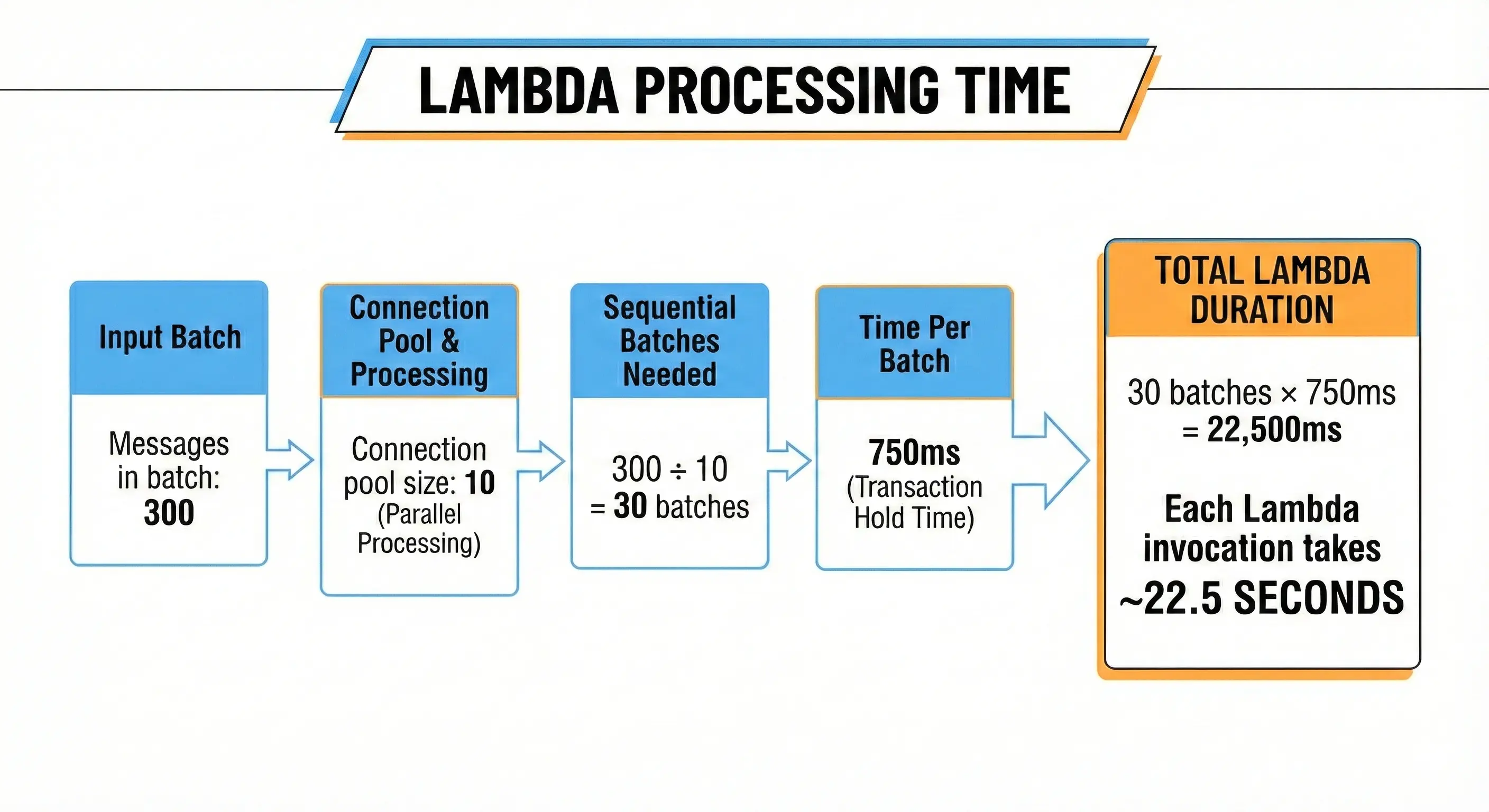
Lambda processing time breakdown: 300 messages per batch, 10-connection pool, 30 sequential batches at 750 ms each, leading to a total Lambda duration of ~22.5 seconds per invocation.
So it takes 22.5 seconds to process a single batch. That might sound acceptable until you realize that new events keep arriving at 300 per second.
The Cascade
Events don't stop arriving while Lambdas are processing. Every second, another batch of events triggers another Lambda, but the previous Lambdas haven't finished yet. Let's look at the image to understand what happens over time:
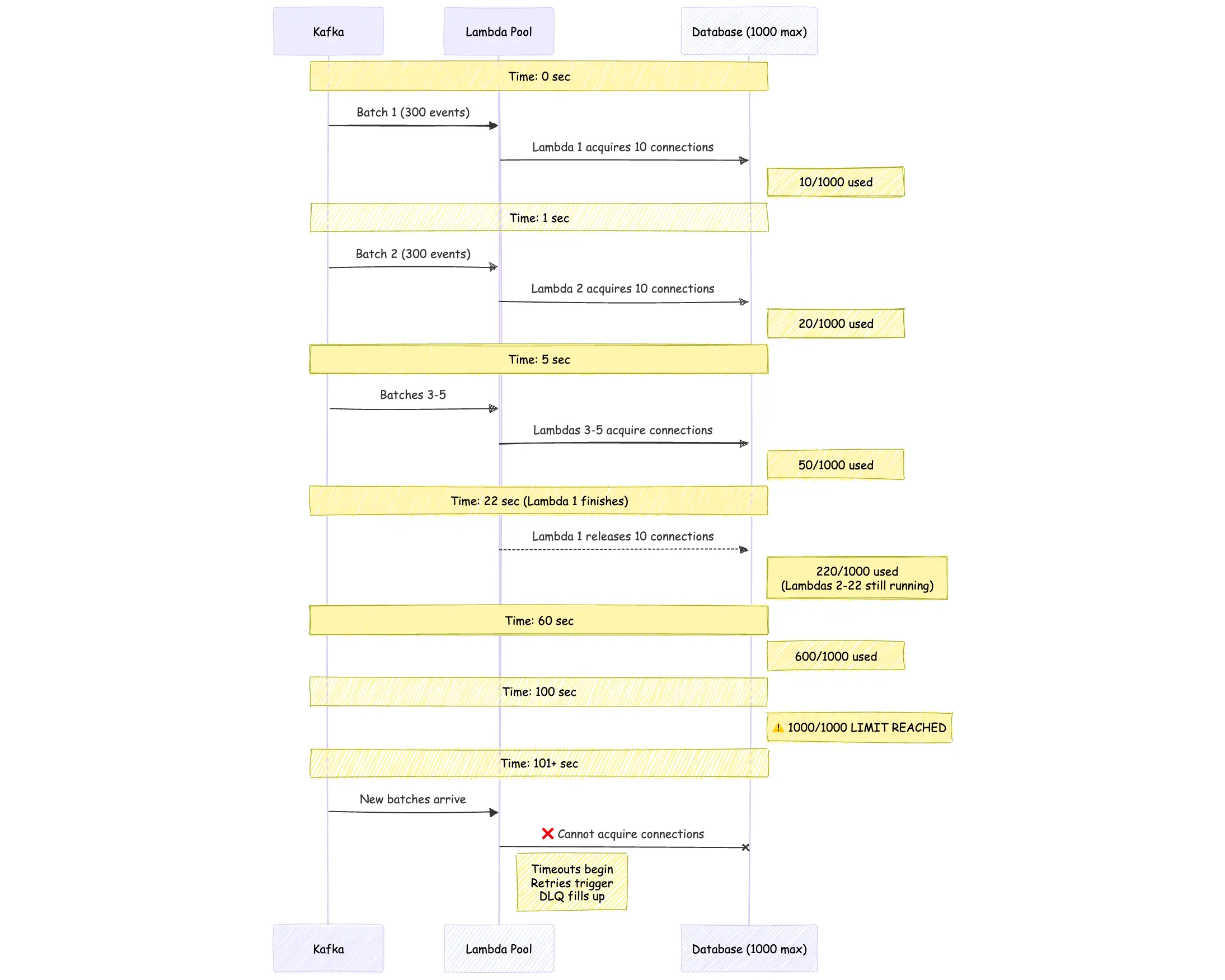
Serverless cascade failure: as each Lambda batch holds database connections for too long, new Lambdas keep spinning up, exhausting the connection pool and pushing the system into timeouts and retries.
The formula is simple but brutal:
Concurrent Lambdas = Event Rate × Lambda Duration ÷ Events per LambdaAt steady state:
Concurrent Lambdas = (300 events/sec × 22.5 sec) ÷ 300 events
Concurrent Lambdas = 6,750 ÷ 300
Concurrent Lambdas ≈ 22-23Connections needed = 23 Lambdas × 10 connections = 230
That seems fine... but what happens when things slow down?
When It Gets Worse
The 22.5-second calculation assumes ideal conditions. In reality, Lambda duration fluctuates due to cold starts, database contention, network latency spikes, and garbage collection pauses.
What happens when Lambda duration increases?
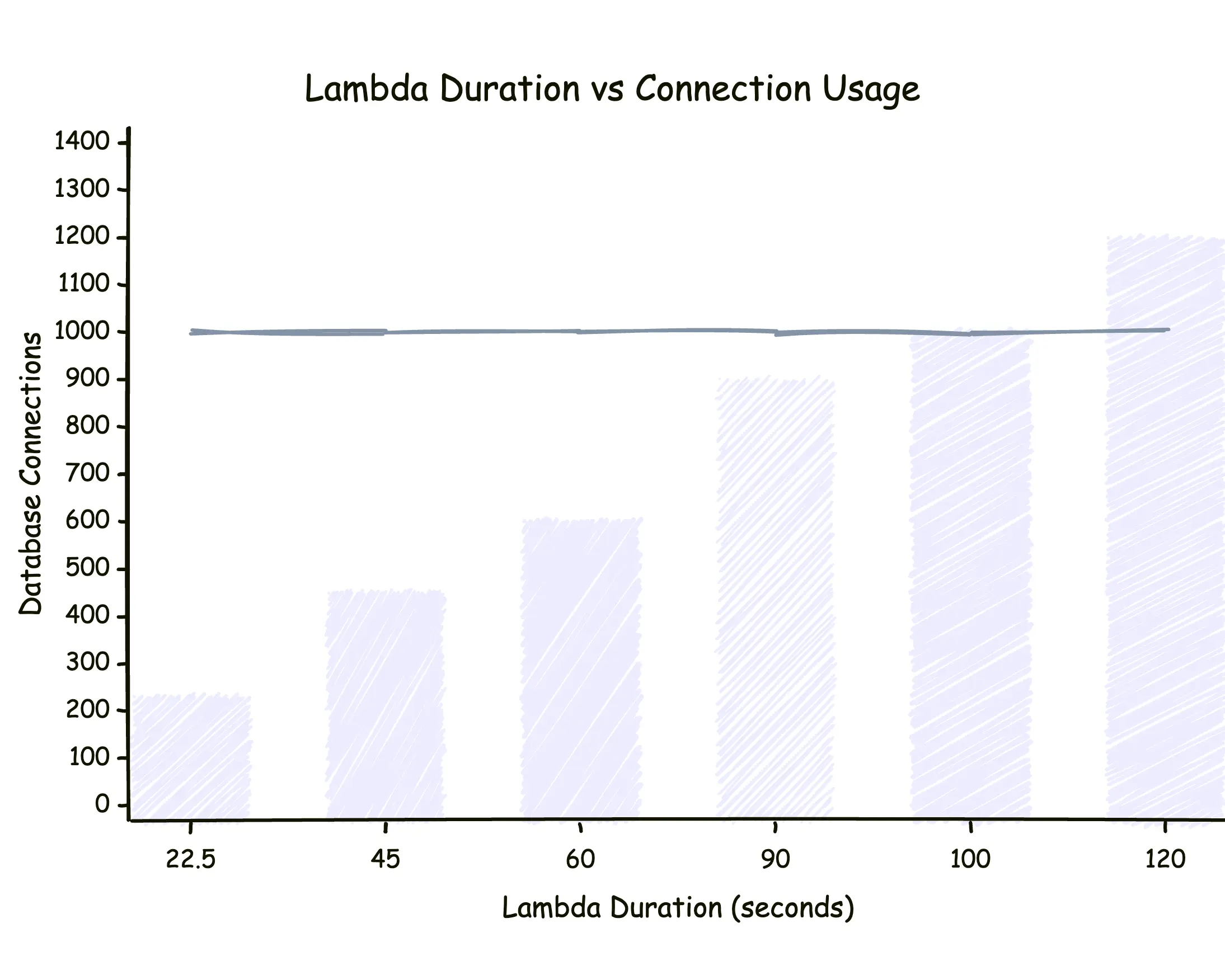
Lambda duration barely changes database connections—until it does. Even as each function runs longer, total connections hover near the limit, showing how slow Lambdas quietly consume your entire connection pool.
The Wrong Fix
When you're running out of database connections, the instinct is to increase the connection pool. More connections per Lambda should help, right?
Let's see:
With a pool size of 10, we process 300 events in 30 batches (300 ÷ 10). Each batch takes 750ms, totaling 22.5 seconds (30 × 750ms). This requires about 23 concurrent Lambdas, using 230 connections (23 × 10).
Now, if we increase the pool size to 20, we process the same 300 events in 15 batches (300 ÷ 20). Each batch still takes 750ms, totaling 11.25 seconds (15 × 750ms). We need only 12 concurrent Lambdas, about half as many. But the connection count becomes 240 (12 × 20), making our situation worse.

When you “fix” connection limits by increasing the pool, you often make it worse. Faster batched Lambdas reduce total connections far more than a bigger pool ever can.
The connection pool size doesn't change the fundamental problem: transaction hold time.
Each transaction still takes 750ms regardless of pool size. More connections just means more transactions running simultaneously, each holding a connection hostage for 750ms.
The Real Problem
Let's look at the formula again:
Total Connections = Concurrent Lambdas × Connections per Lambda
Where: Concurrent Lambdas = Event Rate × Lambda Duration ÷ Batch SizeThe variables we can control:
- Event Rate: Business requirement, can't reduce
- Batch Size: Already optimized
- Connections per Lambda: Increasing makes it worse
- Lambda Duration: 🎯 THIS IS THE KEY
If we can reduce Lambda duration, we reduce concurrent Lambdas, which reduces total connections needed.
The Counterintuitive Solution
We can't make the database faster. We can't reduce the number of tables. We can't eliminate network latency.
But we can reduce the number of transactions.
The insight: transaction overhead (BEGIN, network setup, COMMIT) happens once per transaction. If we put multiple records in one transaction instead of one record per transaction, we amortize that overhead.
Savepoints allow multiple messages to be processed inside one long-lived transaction. Failed messages roll back to their savepoint, while successful messages stay committed—so we get the efficiency of batching without sacrificing isolation.
Why does batching make each message faster?
- One BEGIN/COMMIT instead of ten: ~50ms saved
- Bulk inserts instead of individual inserts: Multiple rows per query
- Connection reuse within transaction: No reconnection overhead
- Reduced network round trips: Batched operations
What Happens When a Message in the Batch Fails?
Batching introduces a risk: if record 5 fails, do you lose records 1-4 that already succeeded?
Savepoints solve this. They're checkpoints within a transaction that allow partial rollback:
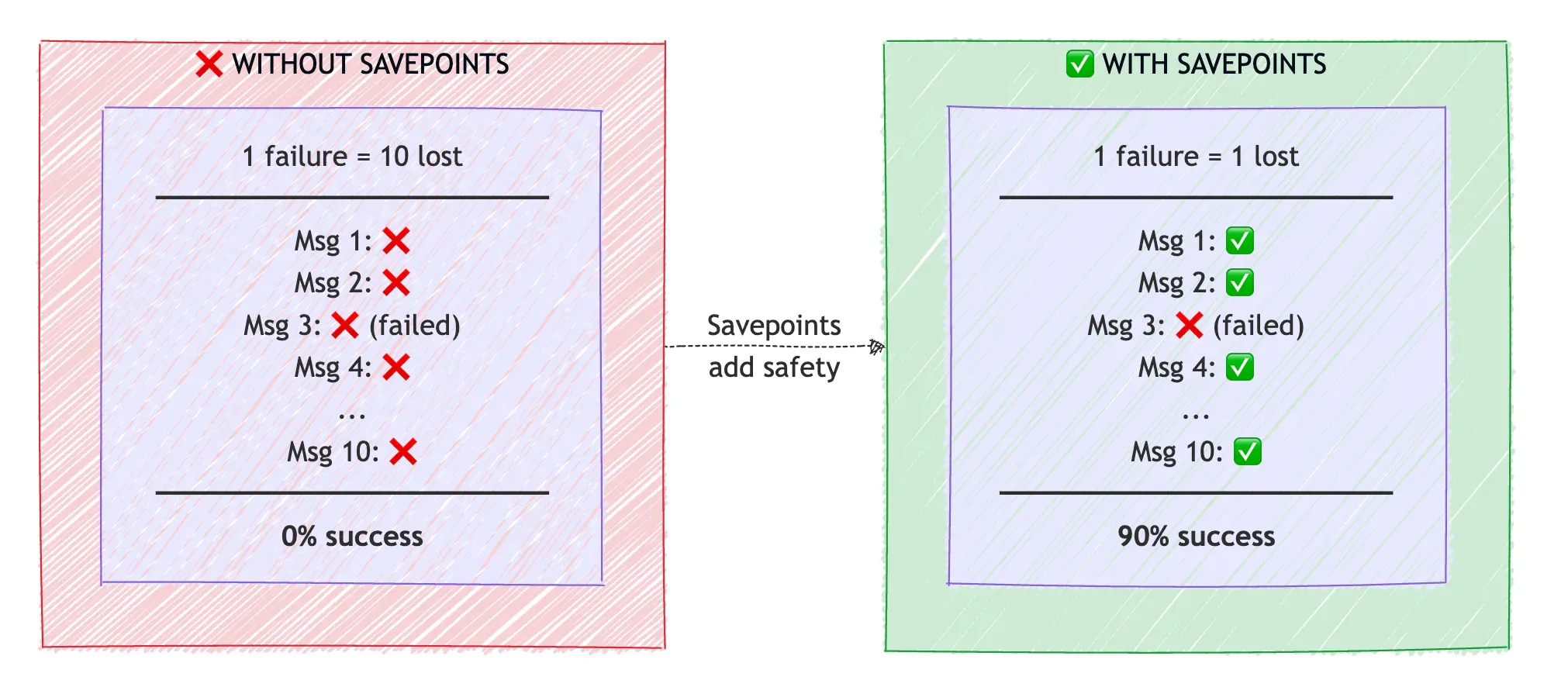
Savepoints give you the efficiency of batching with the reliability of individual transactions.
The New Math
Let's recalculate with batching (30 records per transaction):
BEFORE (1 record per transaction):
Records per batch: 300
Connection pool: 10
Transactions per Lambda: 300
Transaction duration: 750ms
Sequential batches: 30
Lambda duration: 30 × 750ms = 22,500ms (22.5 seconds)AFTER (30 records per transaction):
Record per batch: 300
Connection pool: 10
Transactions per Lambda: 10 (300 ÷ 30)
Transaction duration: 2,000ms (30 records × ~60ms + overhead)
All 10 run in parallel: 2,000ms
Total Lambda duration: ~2 seconds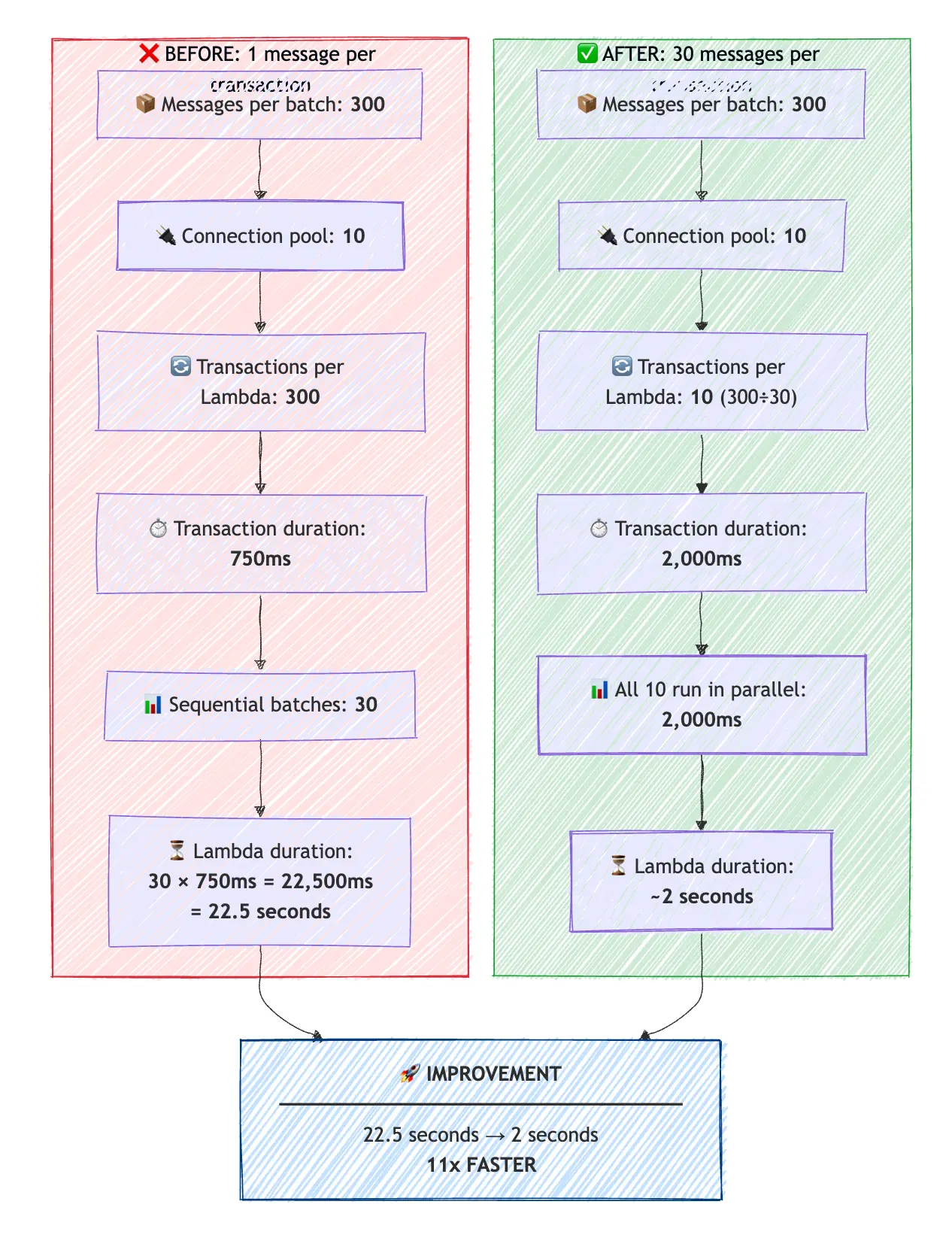
Batching 30 messages per transaction with savepoints cut Lambda duration from 22.5s to ~2s—11x faster and 11x fewer DB connections.
The Results
Summary
| Metric | Before | After | Change |
|---|---|---|---|
| records per transaction | 1 | 30 | 30x |
| Lambda duration | 22.5s | 2s | 11x faster |
| Concurrent Lambdas | 23 | 2 | 11x fewer |
| Connections (steady state) | 230 | 20 | 11x fewer |



%20(1).svg)

.svg)









