


Introduction
When tackling data processing tasks, teams often face a choice between using specialized data engineering tools or adopting solutions that align more closely with their existing expertise. Specialized tools can be incredibly powerful, offering advanced capabilities for distributed processing and complex workflows. However, they often require a deep understanding of specific frameworks or paradigms, which may introduce a learning curve or demand a shift in problem-solving approaches.
For our use case—processing CSV data and storing it in DynamoDB—we sought a solution that would balance scalability, flexibility, and ease of use. AWS Step Functions' distributed map state stood out as an ideal choice. It provides a serverless, low-code approach to orchestrating parallel tasks, making it accessible to developers and engineers without requiring extensive knowledge of distributed data processing frameworks.
By leveraging Step Functions, we can focus on solving the problem at hand while benefiting from its ability to scale efficiently and handle batch processing with minimal overhead. This approach allows us to streamline our workflow and optimize performance without introducing unnecessary complexity.
What to Expect
In this series, I’ll share practical insights and experiences from using the Step Functions Distributed Map State to split a large dataset stored in Amazon S3 into smaller batches or chunks. Each batch will be sent to a batch processing workflow, which uses the Inline Map State to iterate through the records in the batch.
JSONata will serve as the state machine language for data transformation and advanced input/output manipulation. If you’re new to JSONata or wish to learn more about its capabilities, you can refer to its documentation.
We will explore how Step Functions integrates seamlessly with the AWS SDK, allowing workflows to invoke nearly any AWS service API directly. Workflow definitions can be crafted using the Amazon States Language (ASL), visually designed in Workflow Studio within the AWS Console, or constructed locally with the AWS Toolkit for Visual Studio Code.
In Part 1 of this series, we will explain how different map states operate, spotlighting practical use cases and guidance for selecting the right approach.
In Part 2, we will demonstrate how we implemented the solution to process a CSV file containing order records in Amazon S3. We will need to apply simple transformations to before storing the records into DynamoDB, following the partitioning strategy. We’ll also look at Cloudwatch metrics to analyze concurrency behavior and how not to overwhelm downstream resources.
By walking through this approach, we aim to provide actionable insights into leveraging Step Functions for batch processing while helping you make informed decisions about selecting tools that align with your team’s expertise and project requirements.
Solution Architecture Overview
This diagram illustrates the architecture for processing large datasets using AWS Step Functions. The workflow is designed to read a CSV file stored in Amazon S3 and load the processed data into DynamoDB.

Let’s break down the key components:
1. Source CSV in Amazon S3: The process begins with a CSV file stored in an Amazon S3 bucket. This file serves as the input dataset for the workflow. Each order record in the CSV includes the order summary. Following is a sample schema/structure of the CSV data.
{
"orderNumber": "ON123456",
"orderDate": "2025-02-25",
"orderStatus": "OPEN",
"lineItems": 2,
"totalPrice": "106.3"
}2. Orchestrator Workflow: The orchestrator, implemented as a Step Functions state machine, initiates and manages the entire process. It splits the input dataset into smaller batches for parallel processing, enabling scalability.
3. Distributed Map Runs: The Distributed Map State is at the core of this architecture. It divides the workload into multiple child workflows, each responsible for processing a batch of data. These child workflows run concurrently, leveraging Step Functions' ability to execute up to 10,000 parallel workflows.
4. Child Workflows: Each child workflow processes its assigned batch of data. This typically involves invoking Lambda functions or other AWS services to transform and prepare data for storage.
5. Amazon DynamoDB: Once processed, the data from each batch is loaded into an Amazon DynamoDB table. DynamoDB serves as the final destination for storing data. The following sample shows the intended structure for each DynamoDB item.
{
"pk": "ON123456-2025-02-25",
"sk": "ORDER_HEADER",
"orderStatus": "OPEN",
"totalPrice": "106.3"
}6. Distributed Map Output: The results of all child workflows are aggregated and written back to Amazon S3 or another specified location for further analysis or auditing.
This design leverages Step Functions' Distributed Map State to achieve high concurrency and scalability while maintaining simplicity and flexibility in orchestrating complex workflows. By breaking down large datasets into manageable batches and processing them in parallel, this solution ensures efficient handling of big data workloads without overwhelming downstream services like DynamoDB.
Parent Workflow
The parent workflow serves as the orchestrator for the whole operation and is built as a Standard Workflow. Distributed Map State is only supported for Standard workflows. Its role is to divide the input CSV file in Amazon S3 into smaller batches or chunks. Each batch is then passed to a separate child workflow for processing. By running multiple child workflows at once, the main workflow supports scalable and efficient processing of large volumes of data.
Child Workflow
The child workflow or batch processor, processes each batch independently. It performs transformations, and writes the processed data into DynamoDB. By isolating batch processing within individual workflows, this design achieves modularity and ensures that failures or delays in one batch do not impact others.
This architecture enables efficient data processing by leveraging Step Functions' ability to execute nested workflows. The modular separation between Parent and Child Workflows simplifies error handling, monitoring, and scaling.
Map State
AWS Step Functions provides two processing modes for the Map state: Inline and Distributed. Each mode is designed for specific use cases, offering distinct advantages depending on the scale and concurrency needs of your workflow.
Inline Map
The Inline Map State enables you to repeat a series of steps for each item in a collection, such as a JSON array, within the execution context of the workflow. This means that all iterations share the same execution history and logs, which are recorded alongside the workflow's history.
Key Features
- Concurrency Control: Supports up to 40 concurrent iterations, configurable using the
MaxConcurrencyfield. This allows you to balance parallel processing with resource constraints. - Unified Execution History: All iterations are logged within the workflow's execution history, making it easier to trace and debug workflows without switching contexts.
- Input Requirements: Inline mode accepts only a JSON array as input, making it ideal for workflows where data is structured as arrays.
Use Cases
Inline Map State is best suited for workflows that:
- Require limited concurrency (max of 40).
- Need unified execution history for easier monitoring and debugging.
- Operate on smaller datasets or involve lightweight operations.
How Inline Map State Works
The Inline Map State processes each item in the input array sequentially or in parallel (based on MaxConcurrency) within the parent workflow’s execution context. This design is particularly useful for workflows where maintaining a single execution trace is critical or where scalability requirements are modest.
The diagram below illustrates how Inline Map State processes items in a collection:
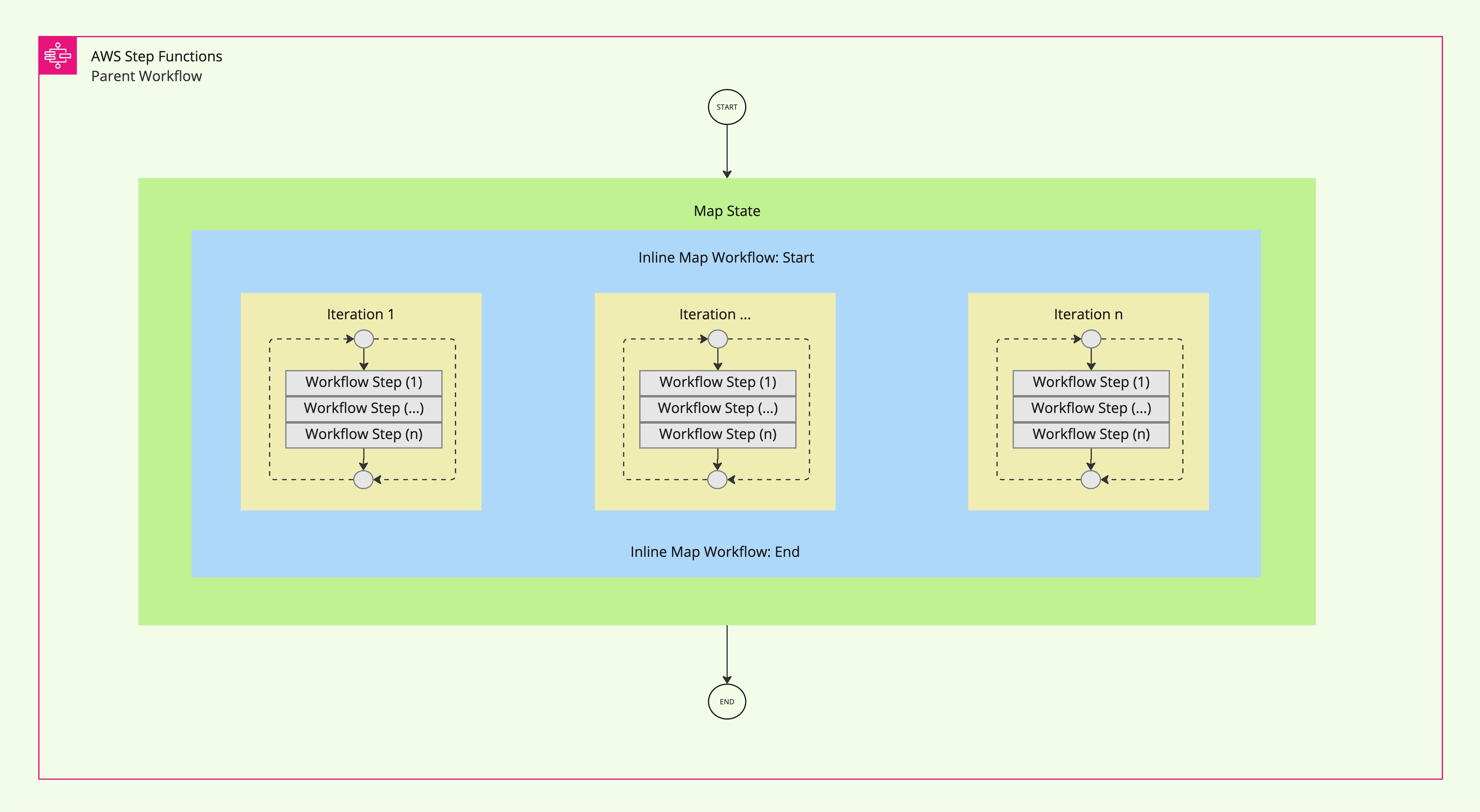
1. The Map State iterates over a collection of items (e.g., JSON array).
2. For each iteration of the map workflow, a series of steps (Workflow Step 1, Workflow Step n) are executed sequentially or concurrently.
3. The results of all iterations are aggregated into the parent workflow’s output.
Distributed Map
The Distributed Map State is a processing mode in AWS Step Functions designed for large-scale parallel data processing. Unlike the Inline Map State, which operates within the execution context of the workflow, Distributed Map state launches child workflows to process each batch in a dataset independently. This makes it ideal for handling massive datasets that exceed the limitations of Inline mode, such as size constraints or concurrency requirements.
Key Features
- High Concurrency: Supports up to 10,000 parallel child workflow executions by default, configurable via the
MaxConcurrencysetting. - Independent Execution Histories: Each child workflow has its own execution history, separate from the parent workflow.
- Flexible Input Sources: Accepts input as a JSON array or references data stored in Amazon S3 (such as CSV files or lists of objects).
- Scalability: Ideal for workloads requiring high concurrency, modularity, and scalability, such as processing millions of S3 objects or transforming large CSV files.
Use Cases
Distributed Map State is particularly useful for:
- Datasets in S3 up to 10 GB in size
- Workflows requiring more than 40 concurrent iterations.
- Scenarios where execution histories would exceed 25,000 entries.
By leveraging Distributed Map State, teams can orchestrate serverless workflows that efficiently process large-scale data while overcoming limitations of Inline mode. This ensures faster processing times and greater flexibility for complex applications.
How Distributed Map State Works
The diagram below illustrates how Distributed Map State orchestrates large-scale parallel processing:
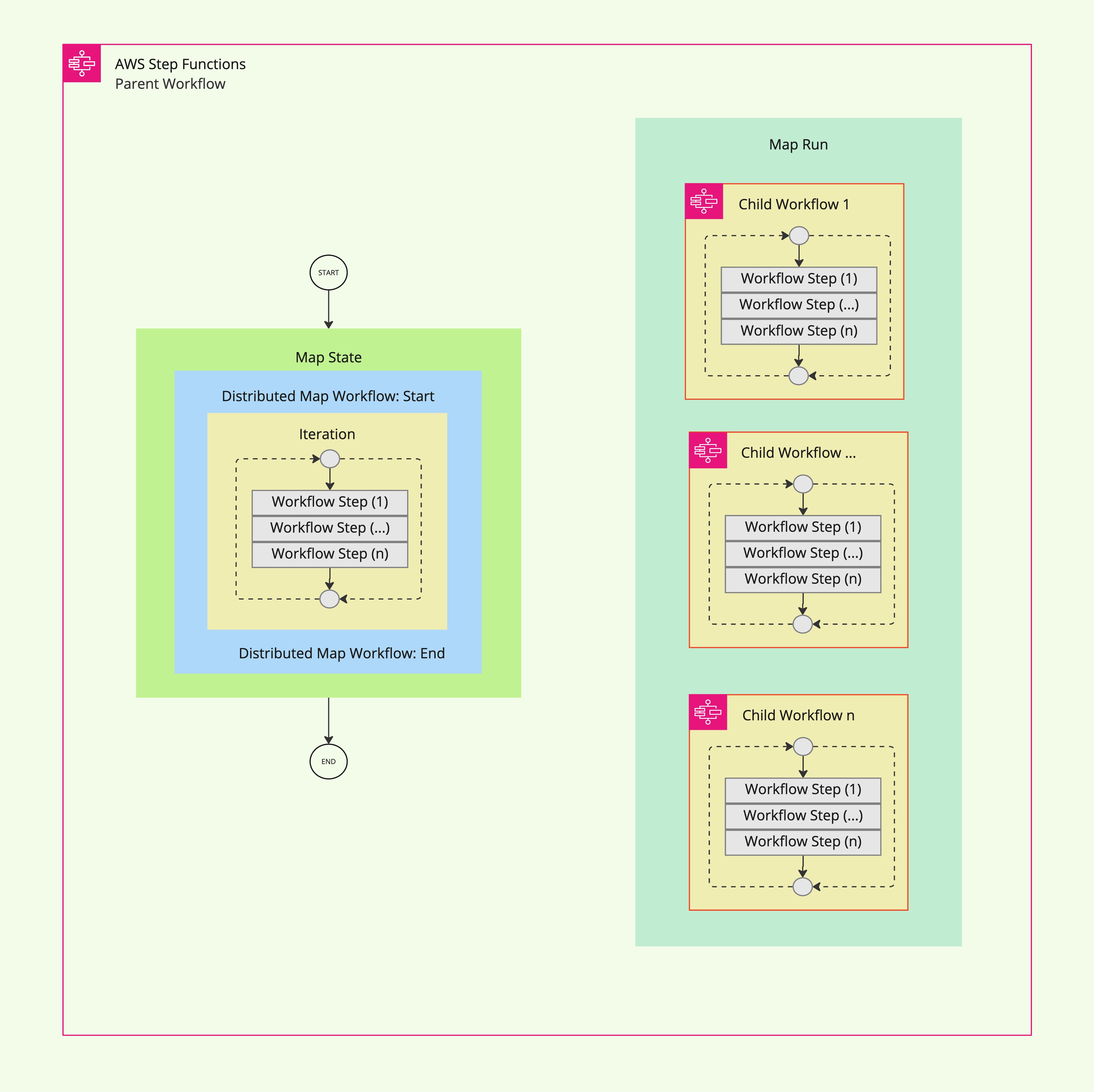
When the parent workflow invokes a Distributed Map State:
- The parent workflow passes either a JSON array or an Amazon S3 data source as input.
- Step Functions creates a Map Run resource to manage the execution of child workflows.
- Each child workflow processes individual items or batches from the dataset independently. These workflows perform specific tasks such as data transformation and validation (e.g., Workflow Step 1 to Workflow Step n).
- Results from all child workflow executions can be aggregated and exported to Amazon S3. See ResultWriter.
This architecture enables high concurrency while maintaining modularity and scalability. It is especially effective for workflows requiring distributed processing across large datasets stored in Amazon S3.
Conclusion
While distributed data processing frameworks, such as Apache Spark and AWS Step Functions Distributed Map State both enable large-scale data processing, they represent fundamentally different paradigms.
Spark is a cluster-based framework optimized for distributed data transformations and analytics, leveraging in-memory computation for high-performance workloads.
In contrast, Distributed Map State offers a serverless orchestration model, ideal for executing parallel workflows across datasets without managing infrastructure.
Depending on the problem at hand, one solution may be more suitable than the other—for example, Spark excels in complex transformations and iterative computations, while Distributed Map State is better suited for lightweight, scalable task orchestration across massive datasets stored in Amazon S3. Understanding these distinctions can help teams choose the approach that aligns best with their requirements and expertise.
The Distributed Map state in AWS Step Functions provides a scalable and efficient way to process large datasets. Its ability to spawn multiple child workflows, process data in parallel, and maintain detailed execution logs makes it perfect for ETL (Extract, Transform, Load) operations and data migrations.
Stay tuned for Part 2 where we will walk through the solution. You’ll see how to set batch sizes, leverage concurrency limits, and monitor execution for large-scale, reliable ETL or data migration pipelines.



%20(1).svg)

.svg)









